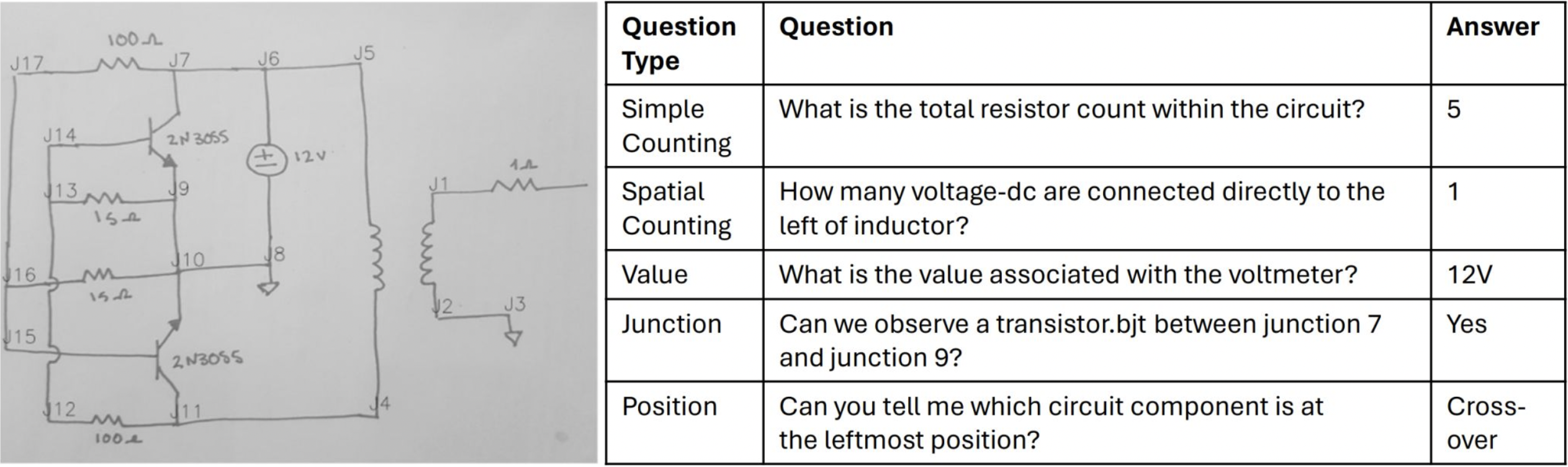
XAlign: Cross-lingual Fact-to-Text Alignment and Generation for Low-Resource Languages
Tushar Abhishek, Shivprasad Sagare, Bhavyajeet Singh, and 3 more authors
In Companion Proceedings of the Web Conference 2022, Virtual Event, Lyon, France, Sep 2022
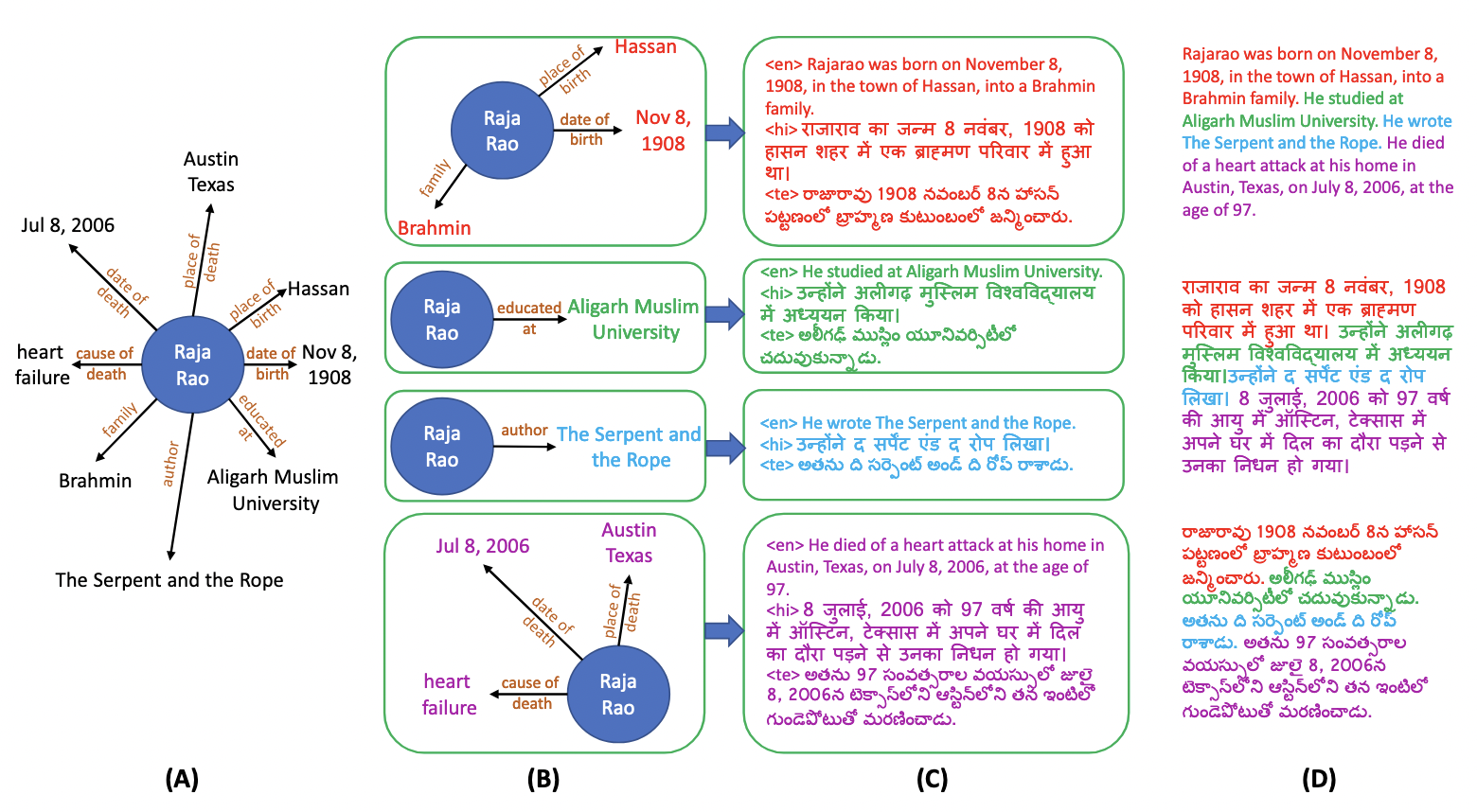
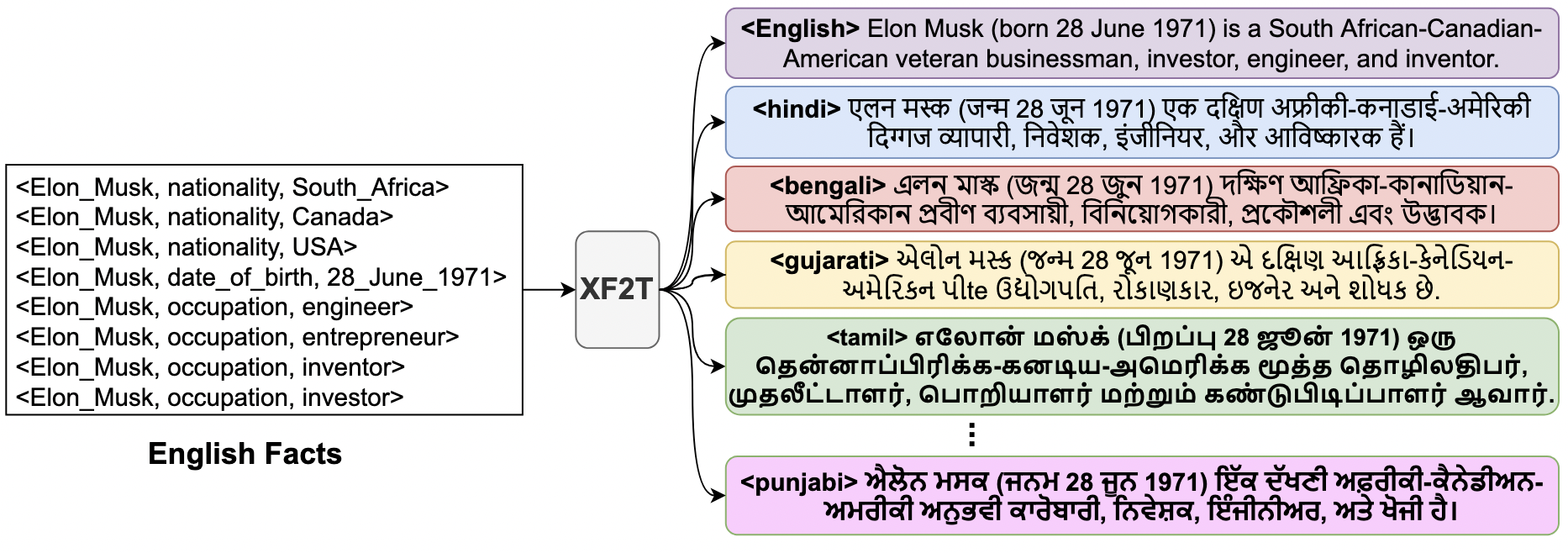
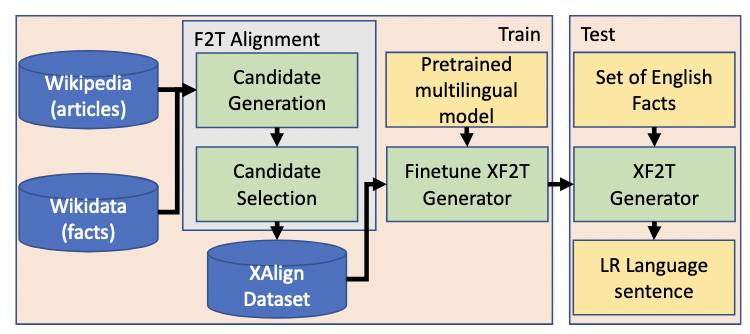
Multiple critical scenarios need automated generation of descriptive text in low-resource (LR) languages given English fact triples. For example, Wikipedia text generation given English Infoboxes, automated generation of non-English product descriptions using English product attributes, etc. Previous work on fact-to-text (F2T) generation has focused on English only. Building an effective cross-lingual F2T (XF2T) system requires alignment between English structured facts and LR sentences. Either we need to manually obtain such alignment data at a large scale, which is expensive, or build automated models for cross-lingual alignment. To the best of our knowledge, there has been no previous attempt on automated cross-lingual alignment or generation for LR languages. We propose two unsupervised methods for cross-lingual alignment. We contribute XAlign, an XF2T dataset with 0.45M pairs across 8 languages, of which 5402 pairs have been manually annotated. We also train strong baseline XF2T generation models on XAlign. We make our code and dataset publicly available1, and hope that this will help advance further research in this critical area.
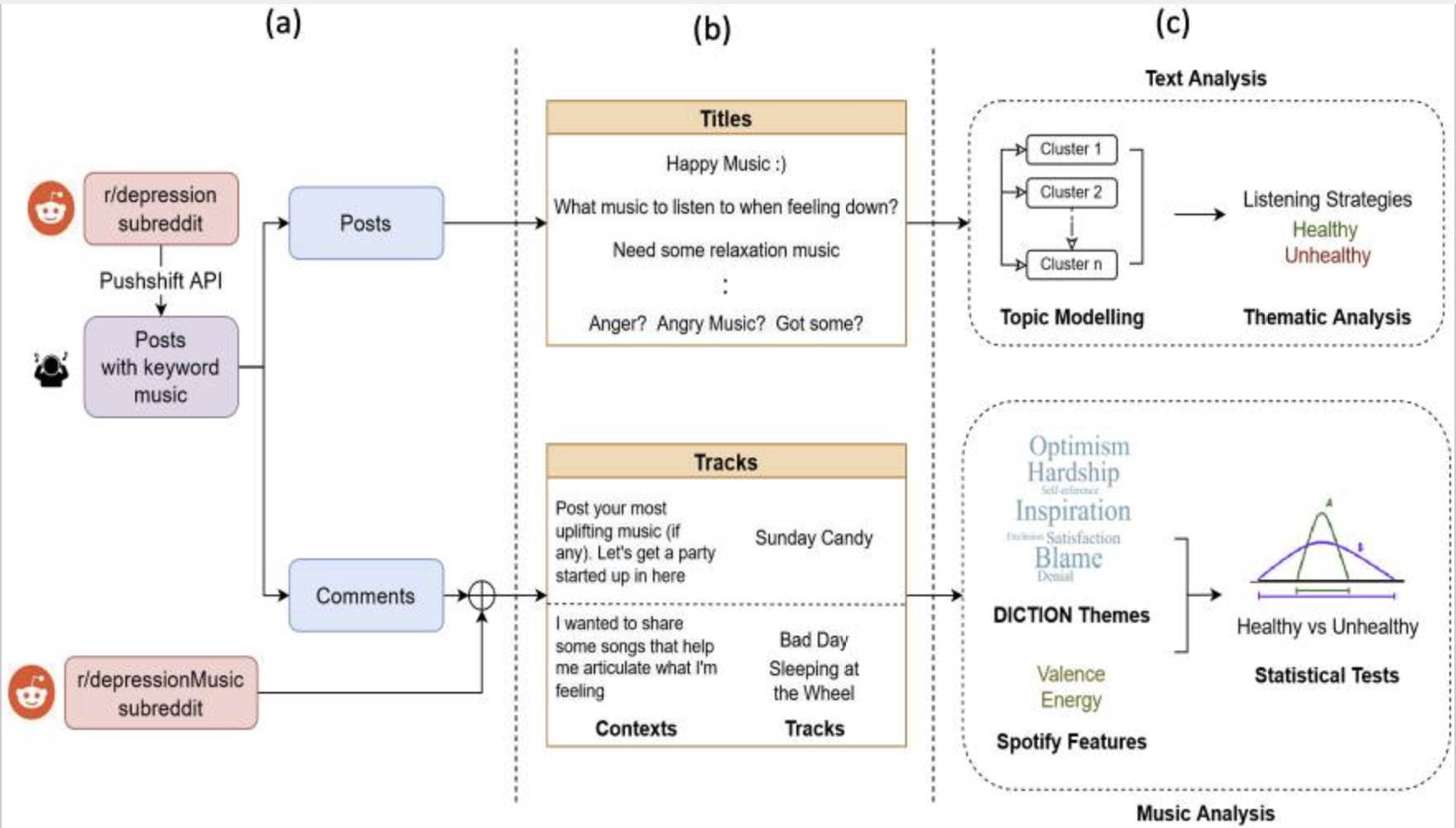
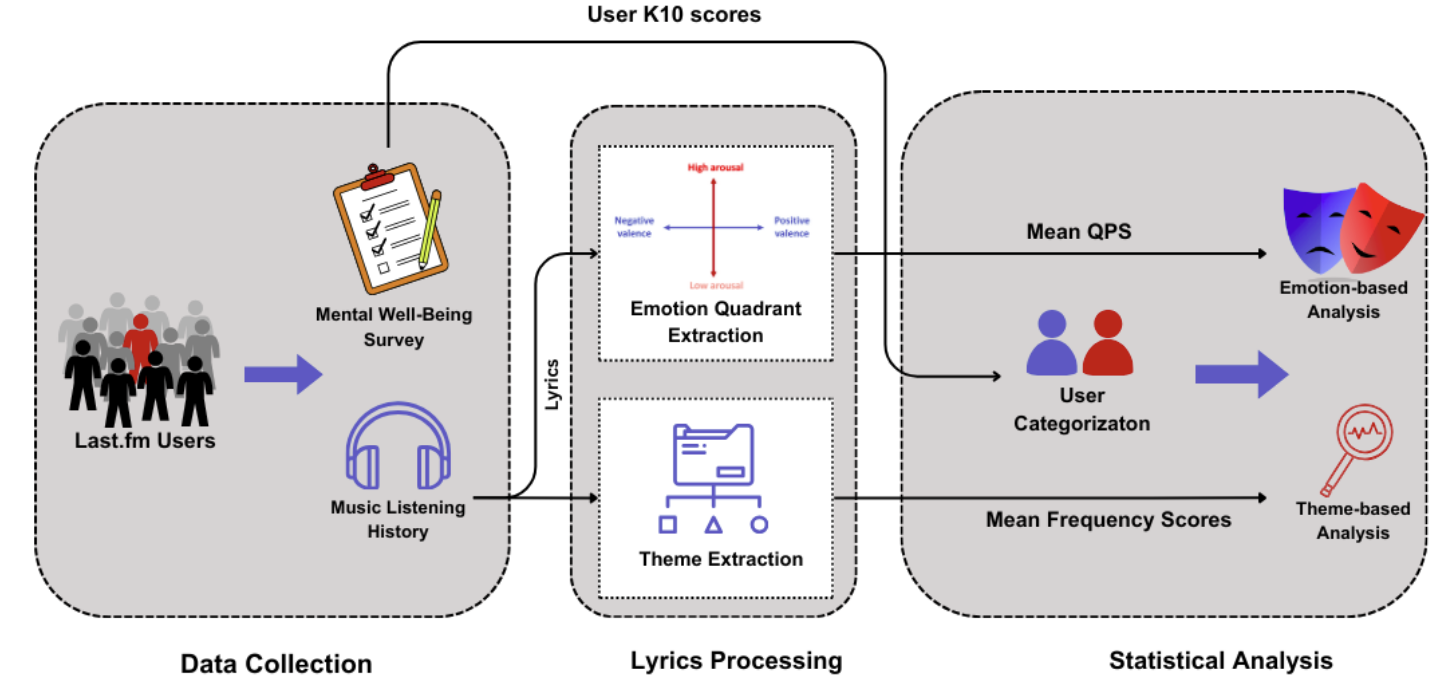 Lyrically Speaking: Exploring the Link Between Lyrical Emotions, Themes and Depression RiskarXiv preprint arXiv:2408.15575, 2024
Lyrically Speaking: Exploring the Link Between Lyrical Emotions, Themes and Depression RiskarXiv preprint arXiv:2408.15575, 2024